在當今數據驅動的時代,大數據技術已成為企業數字化轉型的核心引擎。一張全面的大數據圖譜不僅涵蓋了從數據采集到智能應用的全鏈條,更離不開底層強大的數據處理與存儲支持服務。本文將系統梳理大數據技術生態的關鍵組成部分,并深入解讀數據處理與存儲支持服務的核心價值與實施方案。
一、大數據技術全景圖譜概覽
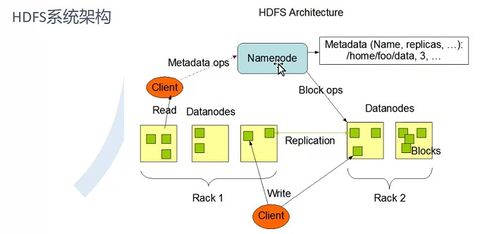
一張完整的大數據圖譜通常包括數據源層、采集層、存儲層、計算層、分析層、應用層以及貫穿始終的管理與安全層。數據源層包含結構化數據(如數據庫)、半結構化數據(如日志、XML)和非結構化數據(如圖像、視頻);采集層通過Flume、Sqoop、Kafka等工具實現高效的數據抽取與實時流接入;存儲層則依托HDFS、NoSQL數據庫(如HBase、Cassandra)、對象存儲(如S3)及數據湖架構,為海量數據提供彈性存儲方案;計算層涵蓋批處理(如MapReduce、Spark)、流計算(如Storm、Flink)和圖計算等多種模式;分析層通過SQL引擎(如Hive)、機器學習庫(如TensorFlow on Spark)及可視化工具實現數據價值挖掘;應用層最終將洞察轉化為推薦系統、風險管控等業務場景。
二、數據處理支持服務:從原始數據到可用資產的轉化樞紐
數據處理是大數據價值鏈中的關鍵環節,其支持服務旨在提升數據質量與可用性。主要包括:
1. 數據清洗與標準化:通過規則引擎或AI去重、補全、修正異常值,確保數據一致性。
2. 數據集成與融合:打破數據孤島,整合多源異構數據,建立統一視圖。
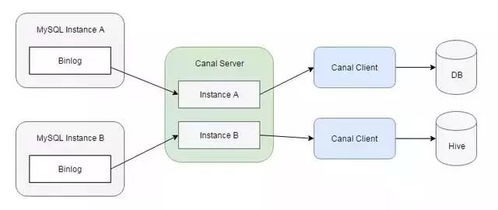
3. 實時流處理:借助Flink等框架,實現毫秒級的數據轉換與事件響應。
4. 數據治理服務:提供元數據管理、血緣追蹤、質量監控等能力,保障數據可信度。
例如,某零售企業通過部署流處理管道,實時聚合線上線下交易日志,在5分鐘內完成用戶行為標簽更新,驅動個性化營銷。
三、數據存儲支持服務:構建可擴展、高可用的數據基石
存儲服務需平衡性能、成本與安全性,常見支持方案包括:
1. 分層存儲策略:根據數據熱度將熱數據置于SSD、溫數據放于HDD、冷數據歸檔至低成本云存儲,優化TCO。
2. 多模數據庫支持:關系型、文檔型、時序數據庫等按場景適配,如用MongoDB存儲商品目錄,用InfluxDB處理IoT時序數據。
3. 數據湖倉一體化:結合數據湖的靈活性與數據倉庫的治理能力,支持原始數據探索與結構化分析并存。
4. 跨云/混合云存儲:通過類似StorReduce的工具實現多云數據同步,避免廠商鎖定。
實踐中,一家物聯網平臺采用“熱數據入時序數據庫+原始數據入數據湖”的混合架構,既滿足實時監控需求,又保留原始數據供AI模型訓練。
四、一體化支持服務的最佳實踐
領先企業正將處理與存儲服務深度融合,形成“存算一體”的支撐體系:
- 云原生數據平臺:基于Kubernetes的容器化部署(如Spark on K8s),實現資源彈性伸縮。
- 自動化運維:通過Prometheus監控集群健康,結合AI預測存儲瓶頸并自動擴容。
- 安全合規增強:集成加密存儲、動態脫敏、審計日志等功能,滿足GDPR等法規要求。
某金融公司通過搭建私有云數據平臺,將交易數據的處理延遲降低60%,同時利用糾刪碼技術將存儲成本壓縮40%。
五、未來趨勢:智能化與綠色節能
隨著技術演進,數據處理與存儲服務正朝著兩個方向進化:一是智能化,即利用機器學習自動優化數據分區、索引及壓縮策略;二是綠色化,通過硬件加速(如GPU處理)和冷熱分離降低能耗。邊緣計算場景下,輕量級存儲框架(如SQLite衍生方案)也將成為補充。
大數據圖譜的完整性與業務價值,高度依賴于底層處理與存儲服務的穩健性。組織在選擇或自建支持服務時,應聚焦業務場景,平衡性能與成本,并預留技術迭代空間。唯有如此,數據才能從負擔轉化為真正的戰略資產,驅動智能決策與創新。拿走這份圖譜與解讀,愿您在數據洪流中穩健航行。